

Kubernetes has quickly become the industry leading platform for container orchestration. But let's face it, Kubernetes can be very complex at times and misconfigurations are inevitable. I am going to take you through some common mistakes so that you can hopefully avoid them!
When talking about Kubernetes on AWS I mean Elastic Kubernetes Service (EKS), Amazons managed Kubernetes service.
Not setting resource memory limits

You may have heard that before: you should set resource requests and limits for your pods. There are a lot of arguments made about this. While resource requests guide the scheduler, resource limits prevent pods from starving their neighbors. If you want to generally learn more about it I recommend reading the K8s resource management docs.
There is one important reason you should set memory limits for your pods if you run Kubernetes with EKS and managed node groups. Some background: By default EKS clusters with managed node groups are controlled by Amazon EC2 auto scaling groups. The auto scaling group is responsible to spawn enough nodes in the right sizes. What it is not doing: removing nodes that have become unresponsive, at least in Kubernetes terms. EC2 has its own health check for instances apart from the one in Kubernetes which involves a connection from the control plane to the kubelet on the node.
Here comes the thing: if your node is memory exhausted, kubelet is suffocated and can't respond to any requests from the control plane anymore. Kubelet is the Kubernetes agent that runs on each of your nodes, manages the pods and reports back to the control plane. While inside the cluster it becomes clear that the node is NotReady when kubelet stops answering and scheduling is disabled for it, our expectation now would be that the autoscaler would also detect it as unhealthy. However, since the EC2 auto scaling group is completely unaware of Kubernetes internals the node just becomes unresponsive but is never removed.
So the learning is: Use memory limits that prevent a pod from consuming all memory of a node. If you are looking for a different solution, you can also use a Kubernetes cluster autoscaler like the default autoscaler.
Using EBS storage with more then one AZ

At some point you probably need some persistent storage in your Kubernetes cluster. You will then find out that there are basically two types of storage available in AWS that you can use as persistent volumes:
- Amazon Elastic File System (EFS), basically an abstraction of NFSv4
- Amazon Elastic Block Storage (EBS), like an external hard drive
Both are valid options and can be integrated into Kubernetes very well. S3 is not an option since it is object storage and persistent volumes have to be block or file system storage.
One important difference between them: EBS volumes are created in one availability zone (AZ) and can not be used in other zones while EFS can span multiple AZs.
So if you have a cluster with nodes in more then one availability zone and a EBS volume in one of them, the pod that mounts that volume has to run on the node that is the same AZ. That means for you: if you have pods that mount that mount persistent volumes and you don't plan to restrict them to a certain AZ you shouldn't use EBS.
Instead there is AWS EFS which you can span multiple availability zones.
Using the default instance templates

By default the number of pods you can run on your cluster nodes is limited by the number of IP addresses that can be assigned to your EC2 instances. For example a t3.small node can run a maximum of 11 pods. You may find yourself in the position that a smaller node is enough for your applications since they might not need a lot of resources but you have a lot of them. But then unfortunately you can't deploy all your pods. The first time I found out about those restrictions was when my scheduler failed to find nodes for my pods.
You can look up how many pods fit onto your nodes by running:
kubectl get nodes -o jsonpath="{range .items[*]}{.metadata.name}: {.status.allocatable.pods}{"\n"}{end}"
There is also a table on Github where you it's listed how many pods fit onto an instance type.
To increase the number of available IP addresses you need to change the instance template. AWS provides a pretty comprehensive article about that:

If you are running a recent Kubernetes version >=1.21, the gist of it is that you have to add some commands to the user data field of the instance template. Here is an example of a shell script that enables container network interface (CNI) prefix delegation and sets the max pods to 110 which is the maximum Kubernetes allows:
#!/bin/bash
set -ex
cat <<-EOF > /etc/profile.d/bootstrap.sh
# This is the magic that permits max-pods computation to succeed
export CNI_PREFIX_DELEGATION_ENABLED=true
export USE_MAX_PODS=false
export KUBELET_EXTRA_ARGS="--max-pods=110"
EOF
# Source extra environment variables in bootstrap script
sed -i '/^set -o errexit/a\\nsource /etc/profile.d/bootstrap.sh' /etc/eks/bootstrap.sh
Using plain secrets in config files
Kubernetes applications need secret values, like a database password or some API keys for external services. Whether you deploy your applications with kubctl apply -f <file.yaml>, Helm chart, or ArgoCD you always want to separate your secret values from your code and configuration files. There are multiple ways to do that, but I want to point out one specific way: Using the Secrets Store CSI Driver and integrate AWS Secret Manager.
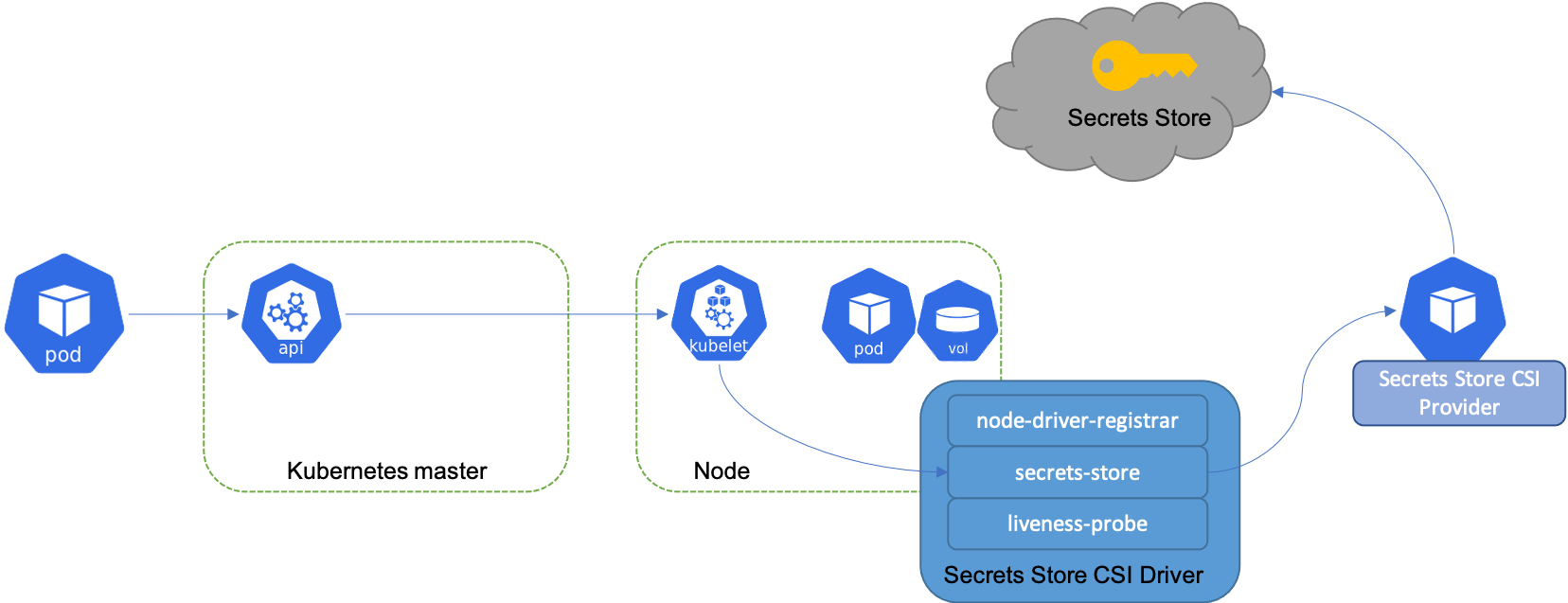
The Kubernetes Secrets Store CSI Driver is a DaemonSet that lets the kubelet retrieve Secrets from external stores, and mount the Secrets as a volume into specific Pods that you authorize to access the data. The secrets mounted into the container become available to your apps via file system. The driver also has an alpha feature that allows you to sync them as Kubernetes secrets and in turn as environment variables. You can find a complete example for that here.
An Ideal setup includes IAM roles for service accounts (IRSA) to implement least privilege. You create IAM roles that are allowed to access one or more secrets and with IRSA you allow only the service account of your pod that needs that secret to assume that IAM role.
AWS provides a comprehensive documentation how to set up the AWS secrete manager with EKS.
Not using version control for your config

This advise is a bit more general and not specific to AWS. When you start out learning Kubernetes you may use kubectl apply a lot to make changes to your cluster. That is alright since you have a lot of trial and error loops and after all it's the fastest way to interact with Kubernetes. However, if you move away from throw-away clusters you should consider version controlling your configurations.
Kubernetes clusters are usually managed by cross-functional-teams. That means that a lot of people are constantly changing the configuration and applying changes to the cluster.
Git version control should be your single source of truth. All changes made to the cluster should be recorded here. An ideal setup includes GitOps pipelines which are the only way changes can be made to cluster resources. You may want to take a look at tools like ArgoCD which make it easy to have continuous delivery pipelines. If you start version controlling the Kubernetes manifests for your applications you may be tempted to have them in the same repository as your code. But think about this: you don't want to run your entire CI pipeline every time you make changes to your deployment configuration. The ArgoCD best practices elaborates the benefits of separating config and code.
Conclusion
Kubernetes is a powerful tool, but it has a steep learning curve and can be prone to errors at times. I hope you found some of the advice helpful and I was able to help you to not make the same mistakes that I have.
Do you need Kubernetes or Go Experts?
We are a Software Agency from Stuttgart, Germany and can support you on your journey to deliver outstanding user experiences and resilient infrastructure. Reach out to us.
Something Else?
Make sure to check out our build tool for large multi-language applications: https://bob.build